Cross-Lingual Transfer Learning for Nepali NLP
Idea in a Nutshell
So, I am interested in training/fine tuning models using little data. For example, we don’t have a lot of data for Nepali Language, but could we come up with ways to map Nepali Language into English Language and then use English data to fine-tune our models?
More Formal Introduction
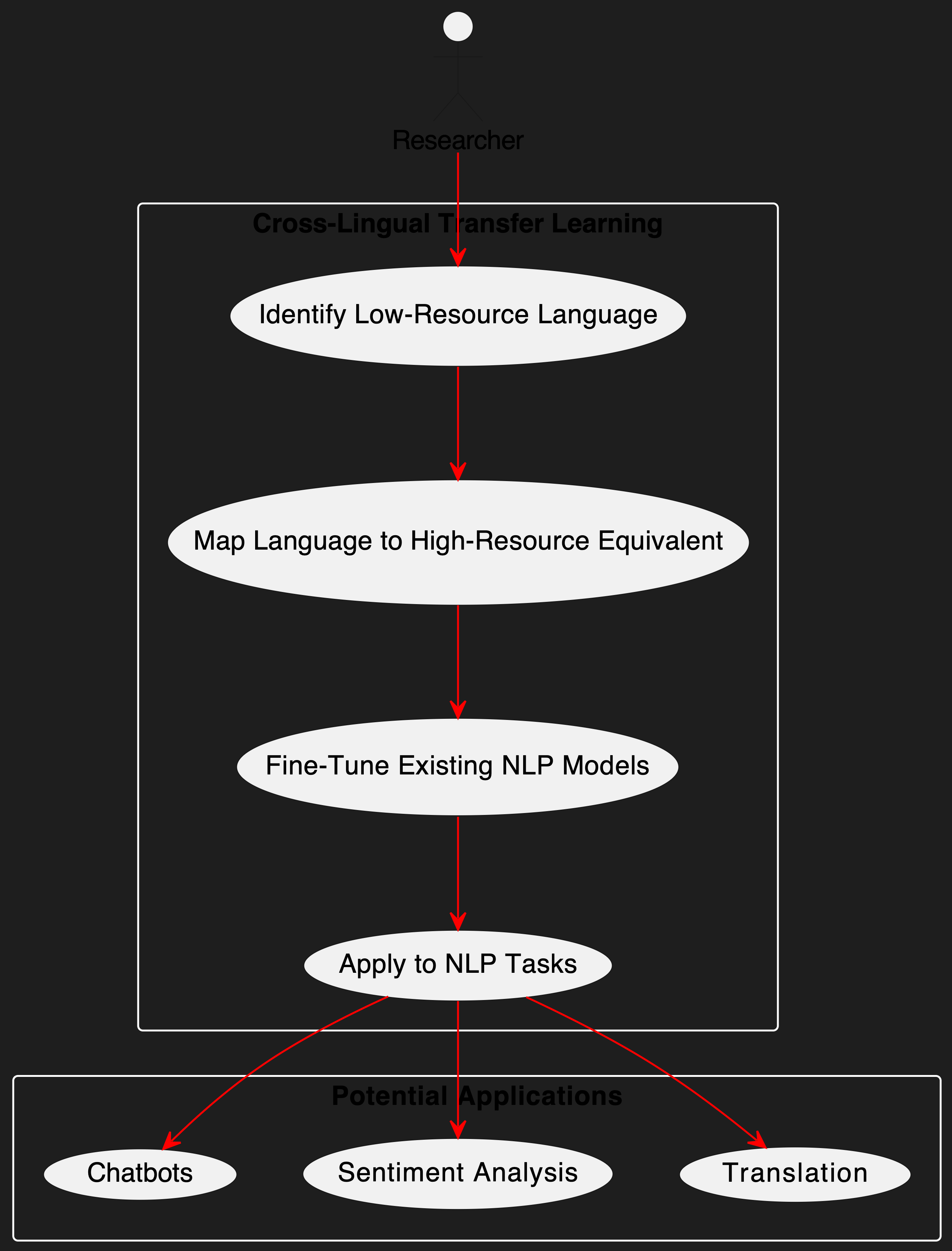
Nepali, a low-resource language, lacks the vast datasets needed for robust NLP applications. Instead of collecting massive datasets, we propose leveraging cross-lingual transfer learning—mapping Nepali to English representations to piggyback on existing English-trained models. The idea is simple: align Nepali text with English using shared embeddings, then use established English models for tasks like sentiment analysis and translation without needing extensive Nepali-specific training data.
Research Objectives
- Map Nepali linguistic structures onto English-trained models to reduce data dependency.
- Explore how well cross-lingual embeddings (XLM-R, mBERT, LASER) capture Nepali semantics.
- Fine-tune pre-trained English models for Nepali NLP tasks using minimal native data.
- Assess the practicality of using transfer learning instead of dataset expansion.
Methodology
Rather than manually building a Nepali NLP dataset, we take an efficiency-first approach:
- Use bilingual embeddings to align Nepali text with English, leveraging existing language models.
- Apply back-translation (Nepali → English → Nepali) to generate synthetic training data.
- Train models to recognize Nepali sentence structures based on similar English datasets.
- Test adaptability by applying these methods to real-world Nepali text classification and translation tasks.
Potential Applications
If successful, this method could be used to quickly build functional NLP systems for languages with limited data. For example, we could:
- Develop Nepali-language chatbots without extensive training data.
- Improve automatic translation for Nepali by leveraging English-Nepali language mapping.
- Build sentiment analysis models for social media content in Nepali, adapted from English classifiers.