Machine Learning for PDF Image Extraction
Idea in a Nutshell
Extracting images from PDFs is a tedious task when done manually. This project explores how Machine Learning can automate image extraction and cropping within PDFs, streamlining workflows for researchers, publishers, and analysts.
Research Objectives
- Develop an ML pipeline that detects and extracts images embedded in PDFs.
- Enhance cropping mechanisms using object detection to remove unnecessary whitespace.
- Optimize extracted images for clarity and format consistency.
- Test performance across different document types (scientific papers, scanned documents, books).
Methodology
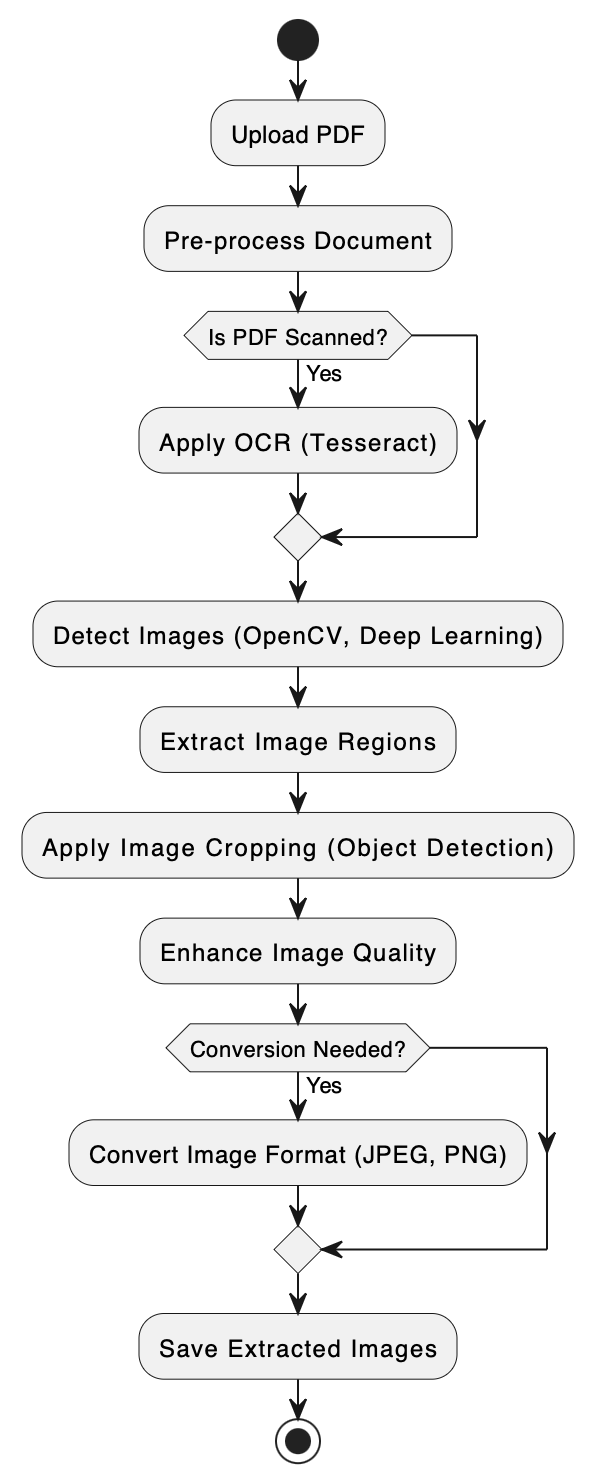
The process involves multiple steps to ensure high-quality image extraction:
- Use **OpenCV** and **Tesseract OCR** to identify image regions within PDFs.
- Apply **Deep Learning-based Object Detection** (YOLO, Faster R-CNN) to refine image boundaries.
- Use **image segmentation** techniques to enhance cropping precision.
- Convert images to appropriate formats (JPEG, PNG) with minimal quality loss.
- Develop a user-friendly interface for uploading and processing PDFs.
Potential Applications
- Automating figure and diagram extraction for research papers.
- Improving document digitization workflows for archival purposes.
- Assisting media and content creators in extracting visuals from reports.
- Enabling AI-driven data visualization by extracting charts and graphs.